Latest copies of all our export formats in one handy package.
February 27, 2020
Pleiades Site News
Pleiades Datasets 2.1 released
December 04, 2019
Pleiades Site News
Nightly Exports Fixed
Incompleteness and validity problems with JSON, CSV, and KML exports are now resolved.
April 10, 2019
Pleiades Site News
Maintenance Complete: 10 April 2019
All scheduled maintenance for 10 April 2019 is now complete.
Maintenance in Progress
Pleiades web services are currently undergoing maintenance.
April 09, 2019
Pleiades Site News
Maintenance 10 April 2019
Pleiades web services will undergo maintenance on Wednesday, 10 April 2019, between 11 am and 5 pm US Eastern Daylight Time.
April 01, 2019
Pleiades Site News
Pleiades Datasets version 1.1
Archival copies of our latest set of platform-independent download data files have been published.
March 11, 2019
Pleiades Site News
Coverage (March 2019)
Pleiades documents 36,541 places as of this morning's JSON update.
December 15, 2017
Pleiades Site News
Improving Reference Citations
Pleiades cites a wide variety of resources, both online and in print. New documentation and tools are making existing references better and easing the process of creating new ones.
October 13, 2017
Horothesia (Tom Elliott)
Using OpenRefine with Pleiades
This past summer, DC3's Ryan Baumann developed a reconciliation service for Pleiades. He's named it Geocollider. It has two manifestations:
- Upload a CSV file containing placenames and/or longitude/latitude coordinates, set matching parameters, and get back a CSV file of possible matches.
- An online Application Programming Interface (API) compatible with the OpenRefine data-cleaning tool.
The first version is relatively self-documenting. This blog post is about using the second version with OpenRefine.Reconciliation
I.e., matching (collating, aligning) your placenames against places in Pleiades.Running OpenRefine against Geocollider for reconciliation purposes is as easy as:
- Download and install OpenRefine.
- Follow the standard OpenRefine instructions for "Reconciliation," but instead of picking the pre-installed "Wikidata Reconciliation Service," select the "Add standard service..." button and enter "http://geocollider-sinatra.herokuapp.com/reconcile" in the service URL dialog, then select the "Add Service" button.
When you've worked through the results of your reconciliation process and selected matches, OpenRefine will have added the corresponding Pleiades place URIs to your dataset. That may be all you want or need (for example, if you're preparing to bring your own dataset into the Pelagios network) ... just export the results and go on with your work.But if you'd like to actually get information about the Pleiades places, proceed to the next section.Augmentation
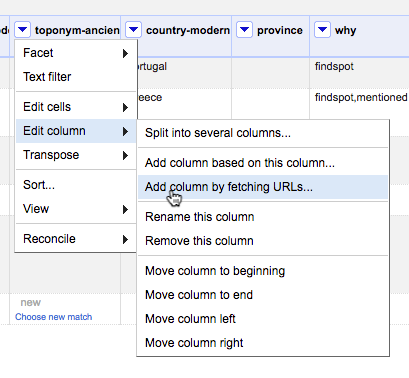
I.e., pulling data from Pleiades into OpenRefine and selectively parsing it for information to add to your dataset.Pleiades provides an API for retrieving information about each place resource it contains. One of the data formats this API provides is JSON, which is a format with which OpenRefine is designed to work. The following recipe demonstrates how to use the General Refine Expression Language to extract the "Representative Location" associated with each Pleiades place.Caveat: this recipe will not, at present, work with the current Mac OSX release of OpenRefine (2.7), even though it should and hopefully eventually will. It has not been tested with the current releases for Windows and Linux, but they probably suffer from the same limitations as the OSX release. More information, including a non-trivial technical workaround, may be had from OpenRefine Issue 1265. I will update this blog post if and when a resolution is forthcoming.1. Create a new column containing Pleiades JSON.Assuming your dataset is open in an OpenRefine project and that it contains a column that has been reconciled using Geocollider, select the drop-down menu on that column and choose "Edit column" -> "Add column by fetching URLs ..."In the dialog box, provide a name for the new column you are about to create. In the "expression" box, enter a GREL expression that retrieves the Pleiades URL from the reconciliation match on each cell and appends the string "/json" to it:cell.recon.match.id + "/json"OpenRefine retrieves the JSON for each matched place from Pleiades and inserts it into the appropriate cell in the new column.
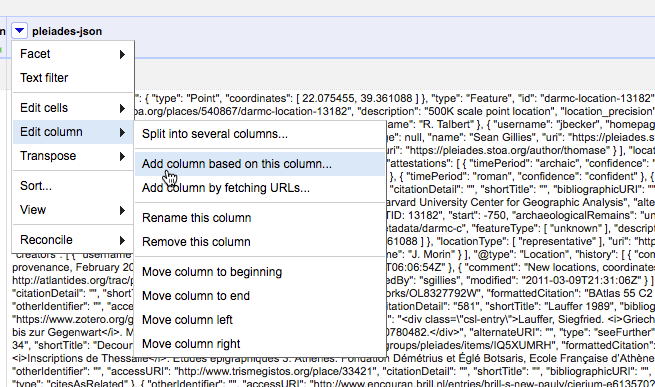
2. Create another new column by parsing the representative longitude out of the JSON.
From the drop-down menu on the column containing JSON, select "Edit column" -> "Add column based on this column..."In the dialog box, provide a name for the new column. In the expression box, enter a GREL expression that extracts the longitude from the reprPoint object in the JSON:value.parseJson()['reprPoint'][0]Note that the reprPoint object contains a two-element list, like:[ 37.328382, 38.240638 ]Pleiades follows the GeoJSON specification in using the longitude, latitude ordering of elements in coordinate pairs so, to get the longitude, you use the index (0) for the first element in the list.3. Create a column for the latitudeUse the method explained in step 2, but select the second list item from reprPoint (index=1).4. Carry on ...Your data set in OpenRefine will now look something like this:



September 29, 2017
Pleiades Site News
Boston Workshop, January 2018
A three-hour workshop on Pleiades and related tools and techniques will be held in Boston on Friday, January 5, 1:45 - 4:45 pm.
August 02, 2017
Stoa
OEDUc: Exist-db mashup application
Exist-db mashup application working
groupThis working group has worked to develop a demo app built with exist-db, a natively XML database which uses XQuery.
The app is ugly, but was built reusing various bits and pieces in a bit less than two days (the day of the unconference and a bit of the following day) and it uses different data sources with different methods to bring together useful resources for an epigraphic corpus and works in most of the cases for the examples we wanted to support. This was possible because exist-db makes it possible and because there were already all the bits available (exist-db, the xslt, the data, etc.)
Code, without data, has been copied to https://github.com/EpiDoc/OEDUc .
The app is accessible, with data from EDH data dumps of July at http://betamasaheft.aai.uni-hamburg.de:8080/exist/apps/OEDUc/
Preliminary twicks to the data included:
- Adding an @xml:id to the text element to speed up retrival of items in exist. (the xquery doing this is in the AddIdToTextElement.xql file)
- Note that there is no Pleiades id in the EDH XML (or in any EAGLE dataset), but there are Trismegistos Geo ID! This is because it was planned during the EAGLE project to get all places of provenance in Trismegistos GEO to map them later to Pleiades. This was started using Wikidata mix’n’match but is far from complete and is currently in need for update.
The features
- In the list view you can select an item. Each item can be edited normally (create, update, delete)
- The editor that updates files reproduces in simple XSLT a part of the Leiden+ logic and conventions for you to enter data or update existing data. It validates the data after performing the changes against the tei-epidoc.rng schema. Plan is to have it validate before it does the real changes.
- The search simply searches in a number of indexed elements. It is not a full text index. There are also range indexes set to speed up the queries beside the other indexes shipped with exist.
- You can create a new entry with the Leiden+ like editor and save it. it will be first validated and in case is not ok you are pointed to the problems. There was not enough times to add the vocabularies and update the editor.
- Once you view an item you will find in nasty hugly tables a first section with metadata, the text, some additional information on persons and a map:
- The text exploits some of the parameters of the EpiDoc Stylesheets. You can
change the desired value, hit change and see the different output.- The ids of corresponding inscriptions, are pulled from the EAGLE ids API here in Hamburg, using Trismegistos data. This app will be soon moved to Trismegistos itself, hopefully.
- The EDH id is instead used to query the EDH data API and get the information about persons, which is printed below the text.
- For each element with a @ref in the XML files you will find the name of the element and a link to the value. E.g. to link to the EAGLE vocabularies
- In case this is a TM Geo ID, then the id is used to query Wikidata SPARQL endpoint and retrive coordinates and the corresponding Pleiades id (given those are there). Same logic could be used for VIAF, geonames, etc. This task is done via a http request directly in the xquery powering the app.
- The Pleiades id thus retrieved (which could be certainly obtained in other ways) is then used in javascript to query Pelagios and print the map below (taken from the hello world example in the Pelagios repository)
- At http://betamasaheft.aai.uni-hamburg.de/api/OEDUc/places/all and http://betamasaheft.aai.uni-hamburg.de/api/OEDUc/places/all/void two rest XQ function provide the ttl files for Pelagios (but not a dump as required, although this can be done). The places annotations, at the moment only for the first 20 entries. See rest.xql.
Future tasks
For the purpose of having a sample app to help people get started with their projects and see some of the possibilities at work, beside making it a bit nicer it would be useful if this could also have the following:
- Add more data from EDH-API, especially from edh_geography_uri which Frank has added and has the URI of Geo data; adding .json to this gets the JSON Data of place of finding, which has a “edh_province_uri” with the data about the province.
- Validate before submitting
- Add more support for parameters in the EpiDoc example xslt (e.g. for Zotero bibliography contained in div[@type=’bibliography’])
- Improve the upconversion and the editor with more and more precise matchings
- Provide functionality to use xpath to search the data
- Add advanced search capabilities to filter results by id, content provider, etc.
- Add images support
- Include all EAGLE data (currently only EDH dumps data is in, but the system scales nicely)
- Include query to the EAGLE media wiki of translations (api currently unavailable)
- Show related items based on any of the values
- Include in the editor the possibility to tag named entities
- Sync the Epidoc XSLT repository and the eagle vocabularies with a webhook
July 05, 2017
Stoa
OEDUc: EDH and Pelagios location disambiguation Working Group
From the beginning of the un-conference, an interest in linked open geodata seemed to be shared by a number of participants. Moreover, an attention towards gazetteers and alignment appeared among the desiderata for the event, expressed by the EDH developers. So, in the second part of the unconference, we had a look at what sort of geographic information can be found in the EDH and what could be added.
The discussion, of course, involved Pelagios and Pleiades and their different but related roles in establishing links between sources of geographical information. EDH is already one of the contributors of the Pelagios LOD ecosystem. Using the Pleiades IDs to identify places, it was relatively easy for the EDH to make its database compatible with Pelagios and discoverable on Peripleo, Pelagios’s search and visualisation engine.
However, looking into the data available for downloads, we focused on a couple things. One is that each of the epigraphic texts in the EDH has, of course, a unique identifier (EDH text IDs). The other is that each of the places mentioned has, also, a unique identifier (EDH geo IDs), besides the Pleiades ID. As one can imagine, the relationships between texts and places can be one to one, or one to many (as a place can be related to more than one text and a text can be related to more than one place). All places mentioned in the EDH database have an EDH geo ID, and the information becomes especially relevant in the case of those places that do not have already an ID in Pleiades or GeoNames. In this perspective, EDH geo IDs fill the gaps left by the other two gazetteer and meet the specific needs of the EDH.
Exploring Peripleo to see what information from the EDH can be found in it and how it gets visualised, we noticed that only the information about the texts appear as resources (identified by the diamond icon), while the EDH geo IDs do not show as a gazetteer-like reference, as it happen for other databases, such as Trismegistos or Vici.
So we decided to do a little work on the EDH geo IDs, more specifically:
- To extract them and treat them as a small, internal gazetteer that could be contributed to Pelagios. Such feature wouldn’t represent a substantial change in the way EDH is used, or how the data are found in Peripleo, but we thought it could improve the visibility of the EDH in the Pelagios panorama, and, possibly, act as an intermediate step for the matching of different gazetteers that focus in the ancient world.
- The idea of using the EDH geo IDs as bridges sounded interesting especially when thinking of the possible interaction with the Trismegistos database, so we wondered if a closer collaboration between the two projects couldn’t benefit them both. Trismegistos, in fact, is another project with substantial geographic information: about 50.000 place-names mapped against Pleiades, Wikipedia and GeoNames. Since the last Linked Past conference, they have tried to align their place-names with Pelagios, but the operation was successful only for 10,000 of them. We believe that enhancing the links between Trismegistos and EDH could make them better connected to each other and both more effectively present in the LOD ecosystem around the ancient world.
With these two objectives in mind, we downloaded the geoJSON dump from the EDH website and extracted the texts IDs, the geo IDs, and their relationships. Once the lists (that can be found on the git hub repository) had been created, it becomes relatively straightforward to try and match the EDH geoIDs with the Trismegistos GeoIDs. In this way, through the intermediate step of the geographical relationships between text IDs and geo IDs in EDH, Trismegistos also gains a better and more informative connection with the EDH texts.
This first, quick attempt at aligning geodata using their common references, might help testing how good the automatic matches are, and start thinking of how to troubleshoot mismatches and other errors. This closer look at geographical information also brought up a small bug in the EDH interface: in the internal EDH search, when there is a connection to a place that does not have a Pleiades ID, the website treats it as an error, instead of, for example, referring to the internal EDH geoIDs. Maybe something that is worth flagging to the EDH developers and that, in a way, underlines another benefit of treating the EDH geo IDs as a small gazetteer of its own.
In the end, we used the common IDs (either in Pleiades or GeoNames) to do a first alignment between the Trismegistos and EDH places IDs. We didn’t have time to check the accuracy (but you are welcome to take this experiment one step further!) but we fully expect to get quite a few positive results. And we have a the list of EDH geoIDs ready to be re-used for other purposes and maybe to make its debut on the Peripleo scene.
July 03, 2017
Stoa
OEDUc: recommendations for EDH person-records in SNAP RDF
At the first meeting of the Open Epigraphic Data Unconference (OEDUc) in London in May 2017, one of the working groups that met in the afternoon (and claim to have completed our brief, so do not propose to meet again) examined the person-data offered for download on the EDH open data repository, and made some recommendations for making this data more compatible with the SNAP:DRGN guidelines.
Currently, the RDF of a person-record in the EDH data (in TTL format) looks like:
<http://edh-www.adw.uni-heidelberg.de/edh/person/HD000001/1> a lawd:Person ; lawd:PersonalName "Nonia Optata"@lat ; gndo:gender <http://d-nb.info/standards/vocab/gnd/gender#female> ; nmo:hasStartDate "0071" ; nmo:hasEndDate "0130" ; snap:associatedPlace <http://edh-www.adw.uni-heidelberg.de/edh/geographie/11843> , <http://pleiades.stoa.org/places/432808#this> ; lawd:hasAttestation <http://edh-www.adw.uni-heidelberg.de/edh/inschrift/HD000001> .We identified a few problems with this data structure, and made recommendations as follows.
- We propose that EDH split the current person references in edh_people.ttl into: (a) one lawd:Person, which has the properties for name, gender, status, membership, and hasAttestation, and (b) one lawd:PersonAttestation, which has properties dct:Source (which points to the URI for the inscription itself) and lawd:Citation. Date and location etc. can then be derived from the inscription (which is where they belong).
- A few observations:
Lawd:PersonalNameis a class, not a property. The recommended property for a personal name as a string isfoaf:name- the language tag for Latin should be
@la(not lat)- there are currently thousands of empty strings tagged as Greek
- Nomisma date properties cannot be used on person, because the definition is inappropriate (and unclear)
- As documented, Nomisma date properties refer only to numismatic dates, not epigraphic (I would request a modification to their documentation for this)
- the D-N.B ontology for gender is inadequate (which is partly why SNAP has avoided tagging gender so far); a better ontology may be found, but I would suggest plain text values for now
- to the person record, above, we could then add
dct:identifierwith the PIR number (and compare discussion of plans for disambiguation of PIR persons in another working group)
June 20, 2017
Stoa
Pleiades sprint on Pompeian buildings
Casa della Statuetta Indiana, Pompei.
Monday the 26th of June, from 15 to 17 BST, Pleiades organises an editing sprint to create additional URIs for Pompeian buildings, preferably looking at those located in Regio I, Insula 8.
Participants will meet remotely on the Pleiades IRC chat. Providing monument-specific IDs will enable a more efficient and granular use and organisation of Linked Open Data related to Pompeii, and will support the work of digital projects such as the Ancient Graffiti.
Everyone is welcome to join, but a Pleiades account is required to edit the online gazetteer.

Pleiades Site News
Pleiades Pompeii sprint
A Pleiades editing sprint in conjunction with the Ancient Graffiti Project (http://ancientgraffiti.org/)
June 19, 2017
Stoa
OEDUc: EDH and Pelagios NER working group
Participants: Orla Murphy, Sarah Middle, Simona Stoyanova, Núria Garcia Casacuberta
Report: https://github.com/EpiDoc/OEDUc/wiki/EDH-and-Pelagios-NER
The EDH and Pelagios NER working group was part of the Open Epigraphic Data Unconference held on 15 May 2017. Our aim was to use Named Entity Recognition (NER) on the text of inscriptions from the Epigraphic Database Heidelberg (EDH) to identify placenames, which could then be linked to their equivalent terms in the Pleiades gazetteer and thereby integrated with Pelagios Commons.
Data about each inscription, along with the inscription text itself, is stored in one XML file per inscription. In order to perform NER, we therefore first had to extract the inscription text from each XML file (contained within <ab></ab> tags), then strip out any markup from the inscription to leave plain text. There are various Python libraries for processing XML, but most of these turned out to be a bit too complex for what we were trying to do, or simply returned the identifier of the <ab> element rather than the text it contained.
Eventually, we found the Python library Beautiful Soup, which converts an XML document to structured text, from which you can identify your desired element, then strip out the markup to convert the contents of this element to plain text. It is a very simple and elegant solution with only eight lines of code to extract and convert the inscription text from one specific file. The next step is to create a script that will automatically iterate through all files in a particular folder, producing a directory of new files that contain only the plain text of the inscriptions.
Once we have a plain text file for each inscription, we can begin the process of named entity extraction. We decided to follow the methods and instructions shown in the two Sunoikisis DC classes on Named Entity Extraction:
https://github.com/SunoikisisDC/SunoikisisDC-2016-2017/wiki/Named-Entity-Extraction-I
https://github.com/SunoikisisDC/SunoikisisDC-2016-2017/wiki/Named-Entity-Extraction-II
Here is a short outline of the steps might involve when this is done in the future.
- Extraction
- Split text into tokens, make a python list
- Create a baseline
- cycle through each token of the text
- if the token starts with a capital letter it’s a named entity (only one type, i.e. Entity)
- Classical Language Toolkit (CLTK)
- for each token in a text, the tagger checks whether that token is contained within a predefined list of possible named entities
- Compare to baseline
- Natural Language Toolkit (NLTK)
- Stanford NER Tagger for Italian works well with Latin
- Differentiates between different kinds of entities: place, person, organization or none of the above, more granular than CLTK
- Compare to both baseline and CLTK lists
- Classification
- Part-Of-Speech (POS) tagging – precondition before you can perform any other advanced operation on a text, information on the word class (noun, verb etc.); TreeTagger
- Chunking – sub-dividing a section of text into phrases and/or meaningful constituents (which may include 1 or more text tokens); export to IOB notation
- Computing entity frequency
- Disambiguation
Although we didn’t make as much progress as we would have liked, we have achieved our aim of creating a script to prepare individual files for NER processing, and have therefore laid the groundwork for future developments in this area. We hope to build on this work to successfully apply NER to the inscription texts in the EDH in order to make them more widely accessible to researchers and to facilitate their connection to other, similar resources, like Pelagios.
June 08, 2017
Pleiades Site News
Introducing Geocollider
A new tool to help you match lists of placenames or geographic locations against the Pleiades gazetteer.
June 07, 2017
Stoa
Open Epigraphic Data Unconference report
Last month, a dozen or so scholars met in London (and were joined by a similar number via remote video-conference) to discuss and work on the open data produced by the Epigraphic Database Heidelberg. (See call and description.)
Over the course of the day seven working groups were formed, two of which completed their briefs within the day, but the other five will lead to ongoing work and discussion. Fuller reports from the individual groups will follow here shortly, but here is a short summary of the activities, along with links to the pages in the Wiki of the OEDUc Github repository.
Useful links:
- All interested colleagues are welcome to join the discussion group: https://groups.google.com/forum/#!forum/oeduc
- Code, documentation, and other notes are collected in the Github repository: https://github.com/EpiDoc/OEDUc
1. Disambiguating EDH person RDF
(Gabriel Bodard, Núria García Casacuberta, Tom Gheldof, Rada Varga)
We discussed and broadly specced out a couple of steps in the process for disambiguating PIR references for inscriptions in EDH that contain multiple personal names, for linking together person references that cite the same PIR entry, and for using Trismegistos data to further disambiguate EDH persons. We haven’t written any actual code to implement this yet, but we expect a few Python scripts would do the trick.2. Epigraphic ontology
(Hugh Cayless, Paula Granados, Tim Hill, Thomas Kollatz, Franco Luciani, Emilia Mataix, Orla Murphy, Charlotte Tupman, Valeria Vitale, Franziska Weise)
This group discussed the various ontologies available for encoding epigraphic information (LAWDI, Nomisma, EAGLE Vocabularies) and ideas for filling the gaps between this. This is a long-standing desideratum of the EpiDoc community, and will be an ongoing discussion (perhaps the most important of the workshop).3. Images and image metadata
(Angie Lumezeanu, Sarah Middle, Simona Stoyanova)
This group attempted to write scripts to track down copyright information on images in EDH (too complicated, but EAGLE may have more of this), download images and metadata (scripts in Github), and explored the possibility of embedding metadata in the images in IPTC format (in progress).4. EDH and SNAP:DRGN mapping
(Rada Varga, Scott Vanderbilt, Gabriel Bodard, Tim Hill, Hugh Cayless, Elli Mylonas, Franziska Weise, Frank Grieshaber)
In this group we revised the status of SNAP:DRGN recommendations for person-data in RDF, and then looked in detail about the person list exported from the EDH data. A list of suggestions for improving this data was produced for EDH to consider. This task was considered to be complete. (Although Frank may have feedback or questions for us later.)5. EDH and Pelagios NER
(Orla Murphy, Sarah Middle, Simona Stoyanova, Núria Garcia Casacuberta, Thomas Kollatz)
This group explored the possibility of running machine named entity extraction on the Latin texts of the EDH inscriptions, in two stages: extracting plain text from the XML (code in Github); applying CLTK/NLTK scripts to identify entities (in progress).6. EDH and Pelagios location disambiguation
(Paula Granados, Valeria Vitale, Franco Luciani, Angie Lumezeanu, Thomas Kollatz, Hugh Cayless, Tim Hill)
This group aimed to work on disambiguating location information in the EDH data export, for example making links between Geonames place identifiers, TMGeo places, Wikidata and Pleiades identifiers, via the Pelagios gazetteer or other linking mechanisms. A pathway for resolving was identified, but work is still ongoing.7. Exist-db mashup application
(Pietro Liuzzo)
This task, which Dr Liuzzo carried out alone, since his network connection didn’t allow him to join any of the discussion groups on the day, was to create an implementation of existing code for displaying and editing epigraphic editions (using Exist-db, Leiden+, etc.) and offer a demonstration interface by which the EDH data could be served up to the public and contributions and improvements invited. (A preview “epigraphy.info” perhaps?)
April 20, 2017
Pleiades Site News
New help topic: Open Pleiades CSV in QGIS
Are you eager to use Pleiades data in a geographic information system? Here's a quick, introductory tutorial.
April 11, 2017
Pleiades Site News
Updated help topic: Add a new connection between two places
"Connections" can be used to express relationships between two places in Pleiades. It's easy to add a new connection.
Last updated
April 06, 2020 10:31 PM
All times are UTC.
All times are UTC.
Subscriptions
-
 Chris Lilley (GRRk: Gallo-Roman Recon ... kinda)
Chris Lilley (GRRk: Gallo-Roman Recon ... kinda)
-
Digging Digitally
-
Evaristo Gestoso Rodriguez (Arke_Geomática)
-
Horothesia (Tom Elliott)
-
-
Pleiades Site News
-
-
-
Sebastian Heath (Mediterranean Ceramics)
-
Shawn Graham (Electric Archaeology)
-